¿Que es el Aprendizaje Automatico?
El aprendizaje automático es un campo de la inteligencia artificial que se dedica a desarrollar algoritmos y técnicas que permiten a las computadoras aprender de forma autónoma. A diferencia de la programación tradicional, donde se escriben reglas y procedimientos específicos para llevar a cabo una tarea, en el aprendizaje automático se utilizan datos y algoritmos para que la computadora aprenda y desarrolle su propia lógica y conocimiento.

Existen varios tipos de aprendizaje automático, cada uno con sus propios enfoques y aplicaciones. Los tres tipos principales son:
- Aprendizaje supervisado: es el más común y se utiliza para clasificar o predecir valores. En este tipo de aprendizaje, se le proporciona al algoritmo un conjunto de datos etiquetados, es decir, con valores conocidos. El algoritmo utiliza estos datos para aprender a reconocer patrones y relaciones, y luego se aplica a nuevos datos para hacer predicciones. Ejemplos de algoritmos de aprendizaje supervisado son Naive Bayes, Regresión Logística, Random Forest, entre otros.
- Aprendizaje no supervisado: es utilizado para descubrir patrones y estructuras en los datos. En este caso, el algoritmo se enfrenta a un conjunto de datos no etiquetados y debe encontrar patrones y relaciones por sí mismo. Ejemplos de algoritmos de aprendizaje no supervisado son K-means, Hierarchical Clustering, Aprendizaje Profundo, entre otros.
- Aprendizaje por refuerzo: se basa en la premisa de que un agente aprende a través de la experiencia y la retroalimentación. El agente realiza acciones y recibe recompensas o castigos en función de estas acciones. A medida que el agente experimenta, va ajustando su comportamiento para maximizar la recompensa. Ejemplos de algoritmos de aprendizaje por refuerzo son Q-learning, SARSA, entre otros.
Además de estos tres tipos principales, también existen otras categorías como el aprendizaje semi-supervisado y aprendizaje de refuerzo continuo.
El aprendizaje automático se aplica en una amplia variedad de campos, desde la medicina hasta la manufactura, la financiera, la agricultura, entre otros. Algunos ejemplos de aplicaciones del aprendizaje automático incluyen:
- Análisis predictivo: utilizando algoritmos de aprendizaje supervisado, se pueden predecir eventos futuros, como fallos en equipos, comportamientos de clientes, entre otros.
- Procesamiento del lenguaje natural: el aprendizaje automático se utiliza para desarrollar sistemas de inteligencia artificial capaces de entender y generar lenguaje humano.
- Visión por computadora: el aprendizaje automático se utiliza para desarrollar sistemas capaces de interpretar imágenes y videos, lo que se utiliza en aplicaciones como la detección de objetos, seguimiento de objetos, entre otros.
- Reconocimiento de patrones: el aprendizaje automático se utiliza para identificar patrones en datos, como los usados en la detección de fraude, análisis de riesgos, entre otros.
- Control de robótica: el aprendizaje automático se utiliza para desarrollar sistemas de control de robótica capaces de aprender y adaptarse a su entorno.
Redes Neuronales
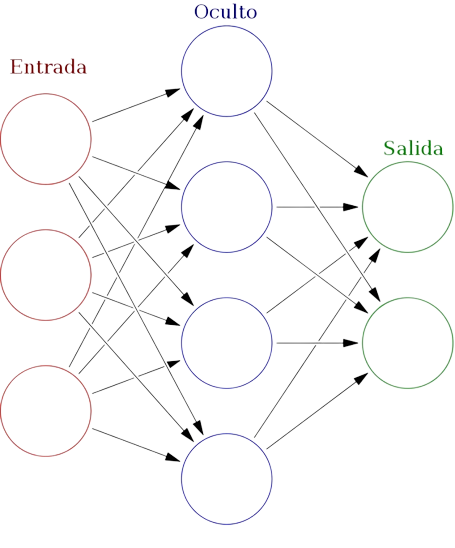
Una red neuronal, también conocida como red neuronal artificial (RNA), es un tipo de modelo de aprendizaje automático que se inspira en la estructura y función del cerebro humano. Una red neuronal se compone de una serie de «neuronas» interconectadas, cada una de las cuales procesa la información que recibe a través de sus «sinapsis» (conexiones) y genera una salida.
La idea básica detrás de una red neuronal es que un sistema complejo, como el cerebro, puede ser dividido en una serie de subsistemas simples (las neuronas) que trabajan juntos para realizar tareas complejas. En el caso de una red neuronal artificial, las tareas incluyen la clasificación, la regresión, la traducción automática, la generación de texto, entre otros.
En esencia, una red neuronal es una función que asigna entradas a salidas. La función se compone de varias capas de nodos (neuronas), cada uno de los cuales realiza una operación matemática específica en los datos de entrada.
Cada neurona en una capa recibe una entrada vectorial, que es un conjunto de valores que representan los datos de entrada. Cada entrada está conectada a la neurona mediante un peso, que se utiliza para ajustar la importancia de cada entrada en la salida final de la neurona. La neurona combina estas entradas ponderadas mediante una función de activación y genera una salida escalar.
La función de activación es una función matemática que se aplica a la salida ponderada de la neurona para regular el rango de salida. Algunas funciones de activación comunes son la función sigmoidal, la función ReLU (Rectified Linear Unit) y la función tangente hiperbólica.
La salida de cada neurona en una capa se utiliza como entrada para las neuronas en la capa siguiente, y este proceso se repite hasta que se alcanza la capa de salida. La salida final de la red neuronal es un vector que representa la salida deseada para los datos de entrada.
El proceso de aprendizaje en una red neuronal se basa en ajustar los pesos de las conexiones entre las neuronas para minimizar una función de pérdida. Este proceso es basado en el algoritmo de retro propagación.
Back propagation
El algoritmo de retropropagación (Backpropagation, en inglés) es un método comúnmente utilizado en el aprendizaje automático para actualizar los pesos de las redes neuronales artificiales. Se trata de un algoritmo de aprendizaje supervisado, es decir, requiere que se le proporcionen ejemplos de entradas y salidas deseadas para poder aprender y mejorar su rendimiento.
La idea detrás del algoritmo de retropropagación es calcular el error de la salida de la red neuronal en comparación con la salida deseada, y luego propagar este error hacia atrás a través de la red, ajustando los pesos de las conexiones entre las neuronas para reducir el error.
La retropropagación se divide en dos fases: propagación hacia adelante y propagación hacia atrás. En la fase de propagación hacia adelante, se utilizan las entradas para calcular la salida de la red neuronal. En la fase de propagación hacia atrás, se calcula el error en la salida y se propaga hacia atrás a través de la red, ajustando los pesos de las conexiones en cada capa.
El algoritmo de retropropagación utiliza una técnica conocida como gradiente descent para ajustar los pesos de las conexiones. El gradiente descent es un algoritmo de optimización que busca encontrar los pesos que minimizan el error en la salida.
En resumen, el algoritmo de retropropagación es una técnica crucial en el aprendizaje automático, especialmente en el campo de las redes neuronales artificiales. Su capacidad para actualizar los pesos de las conexiones entre las neuronas de manera eficiente y automática, permite a las redes neuronales aprender y mejorar su rendimiento a medida que se les proporciona más datos.
Ejemplo de una red neuronal en keras
from keras.models import Sequential from keras.layers import Dense import numpy as np # Crear el modelo de la red neuronal model = Sequential() model.add(Dense(10, input_dim=8, activation='relu')) model.add(Dense(1, activation='sigmoid')) # Compilar el modelo model.compile(loss='binary_crossentropy', optimizer='adam', metrics= ['accuracy']) # Proporcionar datos de entrenamiento y etiquetas x_train = np.random.rand(100,8) y_train = np.random.randint(2, size=(100,1)) # Entrenar el modelo model.fit(x_train, y_train, epochs=10, batch_size=32) # Proporcionar datos de evaluación y etiquetas x_test = np.random.rand(20,8) y_test = np.random.randint(2, size=(20,1)) # Evaluar el modelo scores = model.evaluate(x_test, y_test) print("\n%s: %.2f%%" % (model.metrics_names [1], scores [1]*100))
En este ejemplo, se crea una red neuronal con una capa de entrada de 8 entradas y una capa oculta de 10 neuronas utilizando la función de activación ReLU. La capa de salida tiene una sola neurona y utiliza la función de activación sigmoide. Luego se compila el modelo utilizando la función de pérdida binary_crossentropy y el optimizador Adam.
Después se proporciona al modelo un conjunto de datos de entrenamiento y etiquetas, y se entrena utilizando el método fit() durante 10 épocas con un tamaño de lote de 32. Finalmente se proporciona un conjunto de datos de evaluación y etiquetas para evaluar el rendimiento del modelo y se imprime la precisión del modelo.
